
发布日期:2024-10-04 11:26 点击次数:178
5月21日免息配资平台,国内权威大模型测评机构SuperCLUE正式发布商汤“日日新5.0”(SenseChat V5)中文基准测评结果:以总分80.03分的优异成绩刷新国内最好成绩,并且在中文综合成绩上超越GPT-4-Turbo-0125。
值得注意的是,这是国内大模型首次在SuperCLUE中文基准测试中超越GPT-4 Turbo实现登顶。
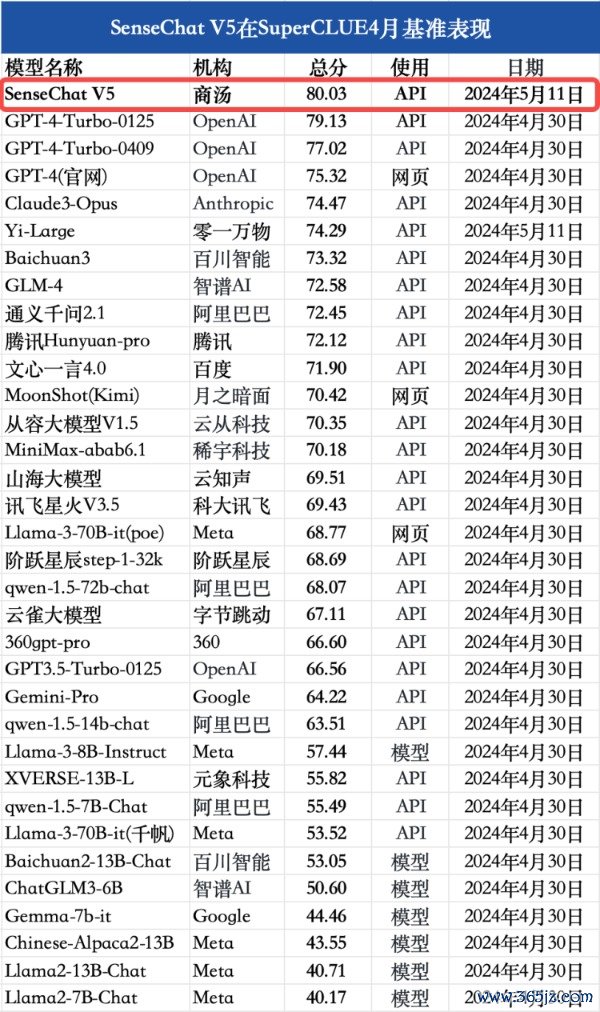
注:对比模型数据均来源于SuperCLUE,SenseChat V5和Yi-Large取自2024年5月11日,其余所有模型取自2024年4月30日。由于部分模型分数较为接近,为了减少问题波动对排名的影响,本次测评将相距0.25分区间的模型定义为并列,以上排序不代表实际排名。 「日日新5.0」文科能力国内外第一
SuperCLUE综合性测评基准4月评测集,有2194道多轮简答题,覆盖理科与文科两大能力,包括计算、逻辑推理、代码、长文本在内的基础十大任务。

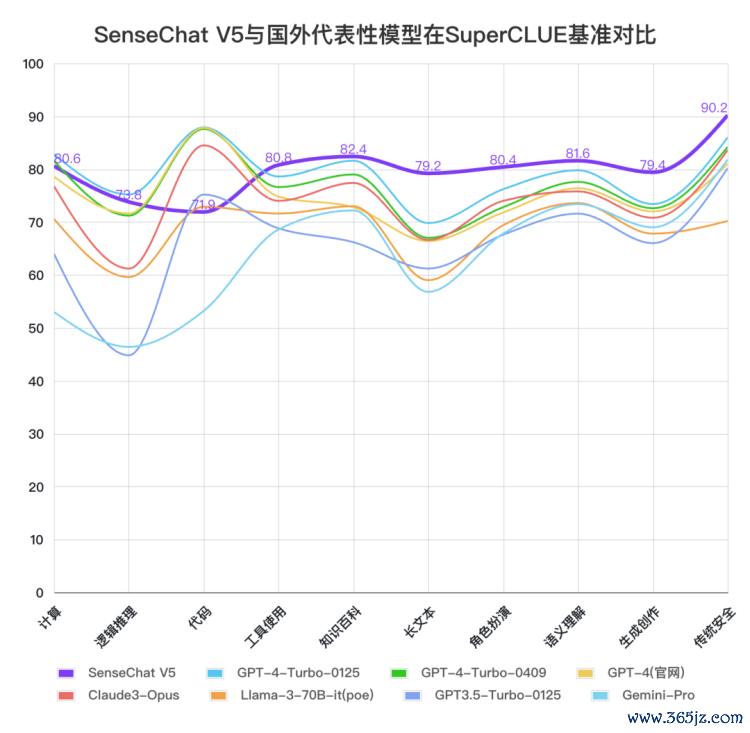
在本次测评中,SenseChat V5在各项能力上表现较为均衡,尤其在长文本、生成创作、角色扮演、安全能力、工具使用上处于全球领先位置。
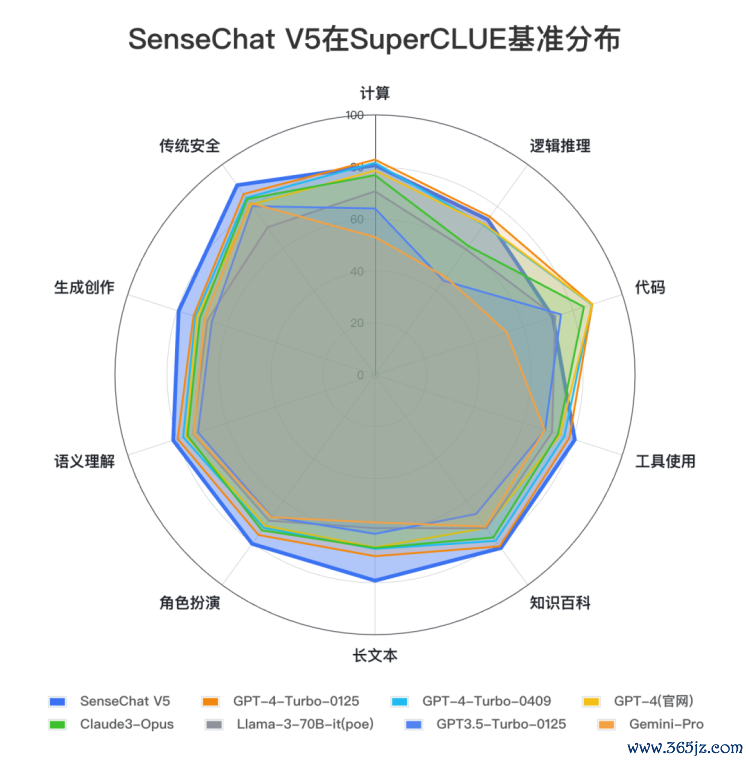
在文科任务上SenseChat V5表现十分出色,以82.20分取得国内外最高分;理科任务上SenseChat V5以76.78分取得国内最好成绩。
SenseChat V5在文科任务上表现出色,取得82.20的高分,国内外模型中排名第一,较GPT-4-Turbo-0125高4.40分。其中,知识百科(82.4)、长文本(79.2)、角色扮演(80.4)、语义理解(81.6)、生成创作(79.4)、传统安全(90.2)均刷新国内最好成绩。

图说:SuperCLUE官方测评“日日新5.0”长文本示例

图说:SuperCLUE官方测评“日日新5.0”生成创作示例
SenseChat V5在理科任务上表现不俗,取得76.78分,国内模型中排名第一。其中,计算(80.6)、逻辑推理(73.8)、工具使用(80.8)均刷新国内最好成绩。

图说:SuperCLUE官方测评“日日新5.0”逻辑推理示例 SuperCLUE:SenseChat V5所有能力均超过国内模型平均线
SuperCLUE工作组发现,将SenseChat V5与国内大模型平均得分对比,SenseChat V5在所有能力上均高于平均线,展现出较均衡的综合能力,尤其在计算(+16.15)、逻辑推理(+18.89)、代码(+19.06)、长文本(+21.16)能力上远高出平均线15分以上。
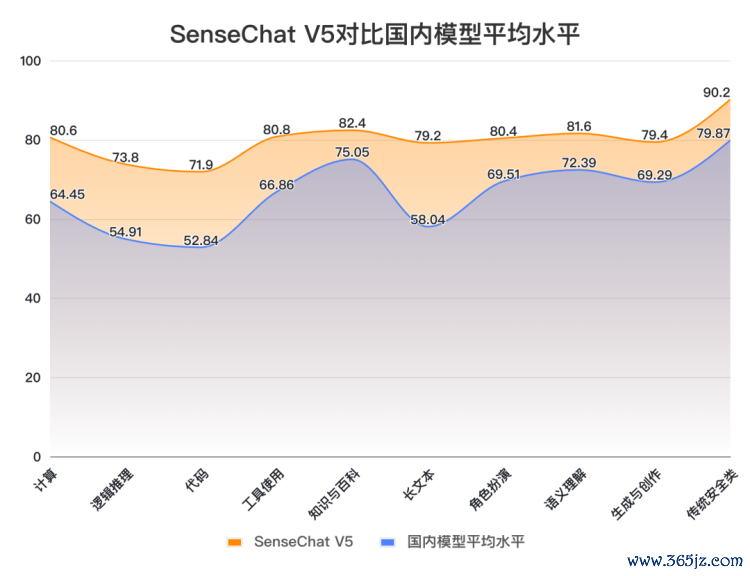
对比数据来源:SuperCLUE, 2024年4月30日
在与国外代表大模型对比时SuperCLUE的工作组发现,SenseChat V5在文科类中文任务上好于国外大模型,尤其在长文本、生成创作能力较为领先。
中国首个GPT-4 Turbo级别的大模型
4月23日,商汤科技正式发布全新大模型日日新5.0(SenseChat V5),采用混合专家架构(MoE),参数量高达6000亿,支持200K的上下文窗口。
此次SenseChat V5模型能力显著提升,其背后是训练数据的全面升级与训练方法的有效提升,以及商汤AI大装置SenseCore算力设施与算法设计的联合调优。
在数据方面,SenseChat V5采用了新一代数据生产管线,生产了10T tokens的高质量训练数据。通过多个模型进行数据的过滤和提炼,显著提升了预料质量和信息密度;基于精细聚类的均衡采样确保对世界知识覆盖的完整性。同时,SenseChat V5还大规模采用了思维型的合成数据(数千亿tokens量级),这对于模型在逻辑推理、数学和编程等方面的能力提升起到了关键作用。
SenseChat V5采用了自研的多阶段训练链路,包括三阶段预训练、双阶段SFT和在线RLHF。通过在每个阶段设定更加清晰聚焦的目标,实现更敏捷的调优,也避免了不同目标之间的相互干扰。
其中在预训练阶段,分阶段培养模型的基础语言和知识能力、长文建模能力、以及复杂逻辑推理能力(规模化采用合成数据);在 SFT 阶段免息配资平台,把任务指令遵循和对话体验优化分解到双阶段进行;在 RLHF 阶段,采用统一的多维度奖励模型和动态系统提示词对多维度偏好进行打分,从而更好地实现模型在多个维度和人类期望对齐。
Powered by 股票配资平台app_实盘配资平台app_专业网上配资炒股 @2013-2022 RSS地图 HTML地图